
Предварительная обработка данных
Анализировать можно как качественные, так и некачественные данные. Результат будет достигнут и в том, и в другом случае. Для обеспечения качественного анализа необходимо проведение предварительной обработки данных, которая является необходимым этапом процесса Data Mining.
Оценивание качества данных. Данные, полученные в результате сбора, должны соответствовать определенным критериям качества. Таким образом, можно выделить важный подэтап процесса Data Mining - оценивание качества данных.
Качество данных (Data quality) - это критерий, определяющий полноту, точность, своевременность и возможность интерпретации данных.
Данные могут быть высокого качества и низкого качества, последние - это так называемые грязные или "плохие" данные.
Данные высокого качества - это полные, точные, своевременные данные, которые поддаются интерпретации.
Такие данные обеспечивают получение качественного результата: знаний, которые смогут поддерживать процесс принятия решений.
О важности обсуждаемой проблемы говорит тот факт, что "серьезное отношение к качеству данных" занимает первое место среди десяти основных тенденций, прогнозирующихся в начале 2005 года в области Business Intelligence и Хранилищ данных компанией Knightsbridge Solutions. Этот прогноз был сделан в январе 2005 года, а в июне 2005 года Даффи Брансон (Duffie Brunson), один из руководителей компании Knightsbridge Solutions, проанализировал состоятельность данных ранее прогнозов.
Сокращенное изложение его анализа представлено в [90]. Ниже изложен прогноз и его анализ полгода спустя.
Прогноз. Многие компании стали обращать больше внимания на качество данных, поскольку низкое качество стоит денег в том смысле, что ведет к снижению производительности, принятию неправильных бизнес-решений и невозможности получить желаемый результат, а также затрудняет выполнение требований законодательства. Поэтому компании действительно намерены предпринимать конкретные действия для решения проблем качества данных.
Реальность.
Данная тенденция сохраняется, особенно в индустрии финансовых услуг. В первую очередь это относится к фирмам, старающимся выполнять соглашение Basel II. Некачественные данные не могут использоваться в системах оценки рисков, которые применяются для установки цен на кредиты и вычисления потребностей организации в капитале. Интересно отметить, что существенно изменились взгляды на способы решения проблемы качества данных. Вначале менеджеры обращали основное внимание на инструменты оценки качества, считая, что "собственник" данных должен решать проблему на уровне источника, например, очищая данные и переобучая сотрудников. Но сейчас их взгляды существенно изменились. Понятие качества данных гораздо шире, чем просто их аккуратное введение в систему на первом этапе. Сегодня уже многие понимают, что качество данных должно обеспечиваться процессами извлечения, преобразования и загрузки (Extraction, Transformation, Loading - ETL), а также получения данных из источников, которые подготавливают данные для анализа.
Рассмотрим понятия качества данных более детально.
Данные низкого качества, или грязные данные - это отсутствующие, неточные или бесполезные данные с точки зрения практического применения (например, представленные в неверном формате, не соответствующем стандарту). Грязные данные появились не сегодня, они возникли одновременно с системами ввода данных.
Грязные данные могут появиться по разным причинам, таким как ошибка при вводе данных, использование иных форматов представления или единиц измерения, несоответствие стандартам, отсутствие своевременного обновления, неудачное обновление всех копий данных, неудачное удаление записей-дубликатов и т.д. Необходимо оценить стоимость наличия грязных данных; другими словами, наличие грязных данных может действительно привести к финансовым потерям и юридической ответственности, если их присутствие не предотвращается или они не обнаруживаются и не очищаются [91].
Для более подробного знакомства с грязными данными можно рекомендовать [92], где представлена таксономия 33 типов грязных данных и также разработана таксономия методов предотвращения или распознавания и очистки данных.
Описаны различные типы грязных данных, среди них выделены следующие группы:
- грязные данные, которые могут быть автоматически обнаружены и очищены;
- данные, появление которых может быть предотвращено;
- данные, которые непригодны для автоматического обнаружения и очистки;
- данные, появление которых невозможно предотвратить.
Рассмотрим наиболее распространенные виды грязных данных:
- пропущенные значения;
- дубликаты данных;
- шумы и выбросы.
Некоторые значения данных могут быть пропущены в связи с тем, что:
- данные вообще не были собраны (например, при анкетировании скрыт возраст);
- некоторые атрибуты могут быть неприменимы для некоторых объектов (например, атрибут "годовой доход" неприменим к ребенку).
- Исключить объекты с пропущенными значениями из обработки.
- Рассчитать новые значения для пропущенных данных.
- Игнорировать пропущенные значения в процессе анализа.
- Заменить пропущенные значения на возможные значения.
Набор данных может включать продублированные данные, т.е. дубликаты.
Дубликатами называются записи с одинаковыми значениями всех атрибутов.
Наличие дубликатов в наборе данных может являться способом повышения значимости некоторых записей. Такая необходимость иногда возникает для особого выделения определенных записей из набора данных. Однако в большинстве случаев, продублированные данные являются результатом ошибок при подготовке данных.
Как мы можем поступить с продублированными данными?
Существует два варианта обработки дубликатов. При первом варианте удаляется вся группа записей, содержащая дубликаты. Этот вариант используется в том случае, если наличие дубликатов вызывает недоверие к информации, полностью ее обесценивает.
Второй вариант состоит в замене группы дубликатов на одну уникальную запись.
Шумы и выбросы.
Выбросы - резко отличающиеся объекты или наблюдения в наборе данных.
Шумы и выбросы являются достаточно общей проблемой в анализе данных. Выбросы могут как представлять собой отдельные наблюдения, так и быть объединенными в некие группы. Задача аналитика - не только их обнаружить, но и оценить степень их влияния на результаты дальнейшего анализа. Если выбросы являются информативной частью анализируемого набора данных, используют робастные методы и процедуры.
Достаточно распространена практика проведения двухэтапного анализа - с выбросами и с их отсутствием - и сравнение полученных результатов.
Различные методы Data Mining имеют разную чувствительность к выбросам, этот факт необходимо учитывать при выборе метода анализа данных. Также некоторые инструменты Data Mining имеют встроенные процедуры очистки от шумов и выбросов.
Визуализация данных позволяет представить данные, в том числе и выбросы, в графическом виде. Пример наличия выбросов изображен на диаграмме рассеивания на рис. 18.1. Мы видим несколько наблюдений, резко отличающихся от других (находящихся на большом расстоянии от большинства наблюдений).
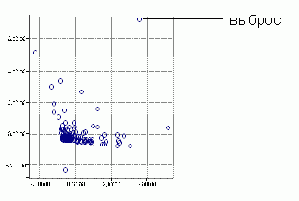
Рис. 18.1. Пример набора данных с выбросами
Очевидно, что результаты Data Mining на основе грязных данных не могут считаться надежными и полезными. Однако наличие таких данных не обязательно означает необходимость их очистки или же предотвращения появления. Всегда должен быть разумный выбор между наличием грязных данных и стоимостью и/или временем, необходимым для их очистки.